
Bei uns war es im Rahmen der Integration einer Google Search Appliance bereits in einem Intranet aufgetreten. PDF-Titel mit verdoppelten Buchstaben auf der Trefferliste. Und so sieht es aus:

Und so sieht das Originaldokument aus. Auf den ersten Blick unauffällig. Macht Google eine Fehler bei der HTML-Konversion?
Schon Ideen? Ein Blick auf die HTML-Version (View as HTML) zeigt auch nichts besonderes, ausser wenn ich den Text markieren…
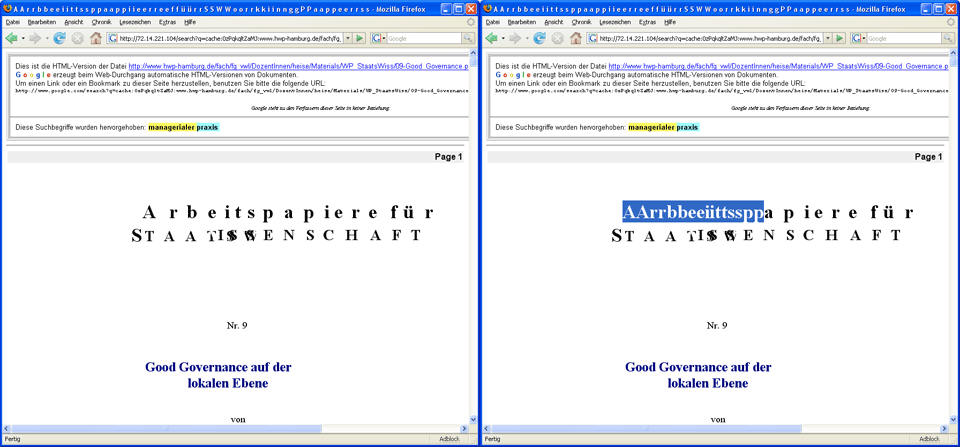
Gott behüte uns! Da hat der Autor die Schrift mir einem Schatteneffekt “verschönert” und das Programm hat diesen Effekt damit erzeugt, dass der Buchstabe leicht versetzt doppelt gedruckt wurde. Im PDF waren die Buchstaben somit doppelt. Uff und ich dachte schon Logopädie müsse her 😉
Google stottert?!
G
Tja! Mit text-shadow wäre das nicht passiert. Aber das wird wohl von den meisten Browser-Herstellern nie implementiert werden.
This “shading” effect is done in some cases with twice the words in different colours with a slight skew.
It looks like it was done this way here also.
We had this issue to fix in our ASAAP tool (PDF -> XML/HTML) in the past. It seems that Google still has to do it 😉
See http://blog.publiconnect.ch/archives/45
;-)) Der ist köstlich! .. Und habt Ihr schon ein Workaround?
@Milos. Workaround wäre wohl den Shading-Knopf in der Software (Word?) auszubauen… Einfluss auf den PDF-Konverter von Google (bei das Appliance) hast Du nicht. Zudem ist das Ding sonst sehr gut.
In dem Projekt ASAAP (PDFs zerschneiden, Text extrahieren und Semantik reinraten) haben wir eine Heuristik die so was verhindert (vgl. Kommentar von Didier oben).