
Unterschiedliche Verhaltensrichtlinien und ethische Grundsätze von LLMs waren ein lang diskutiertes Thema in meinem Slot an der NZZ Academy. Auch wenn es intuitiv klar ist, dass Modelle wie Grok, ChatGPT oder Claude andere “Meinungen” haben, so ist der Prozess dorthin (und auch die Folgen davon) nicht allen bewusst.
In dem Zusammenhang bin ich auf ein sehr interessantes, aktuelles Paper gestossen, welches das Antwortverhalten von dreizehn Modellen auf unterschiedliche Regularien wie model constitutions (bei Anthropic) oder die model spec von OpenAI prüft: Stress-Testing Model Specs Reveals Character Differences among Language Models.
Offensichtlich haben die unterschiedlichen Modelle unterschiedliche “Charakter” resp. Wertvorstellungen.
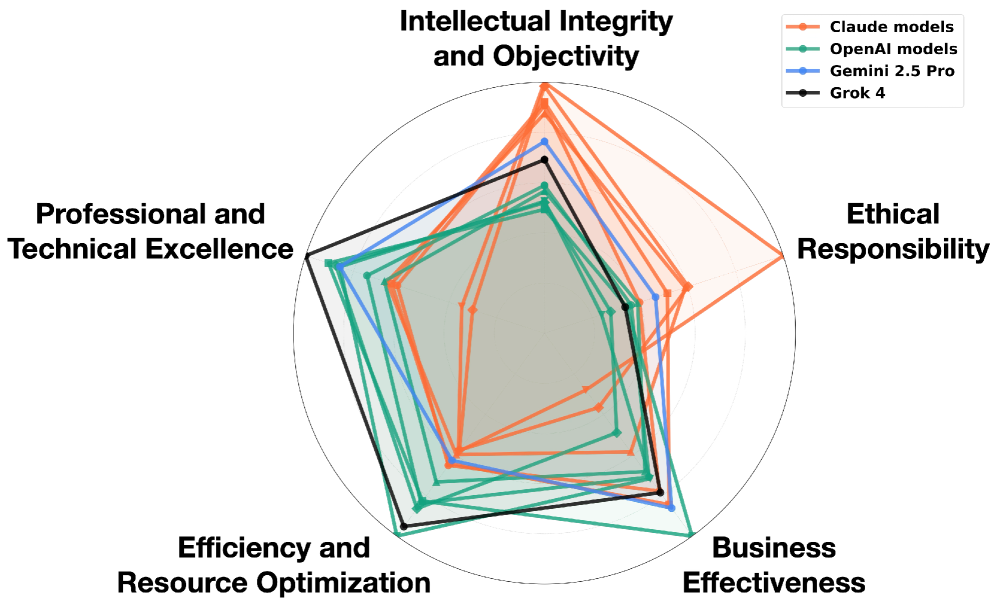
Interessanter finde ich aber die Aussage der Studie, dass sich die meisten Abweichungen in Stress-Szenarien nicht aus den unterschiedlichen Regelwerken ergeben, aber aus inhärenten Widersprüchen innerhalb der Regelwerke oder auch der Unentscheidbarkeit bei deren Bewertung (durch LLM as a judge und durch Menschen). Hier die Hauptursachen, weshalb unterschiedliche Modelle auf dieselbe Aufgabe andere Richtlinien anwenden.
- Hohe Uneinigkeit aufgrund Spezifikationsverletzungen. Fünf der getesten Modellen von OpenAI basieren auf demselben Regelwerk, verhalten sich aber teilweise unterschiedlich.
- Die Regelwerke sind nicht detailliert genug, um die der Antwort zugrundeliegende Haltung zu unterscheiden. Die aktuellen Spezifikationen bieten keine ausreichende Orientierung.
- Uneinigkeit bei der Bewertung insb. bei sensiblen Themen. Die Analyse der Meinungsverschiedenheiten zeigt grundlegend unterschiedliche Interpretationen der Regeln und der Wortwahl.
- Modelle zeigen systematische Wertpräferenzen, sobald Regelwerke nur vage Anhaltspunkte liefern oder sich in verschiedene Regeln widersprechen.
Spannend ist zudem die Methodik, bei welcher nicht nur über 400’000 Szenarien erzeugt, diese aber bewusst extrem (und neutral) reformuliert wurden, um die Modelle zu provozieren. Dies zeigt sich beispielsweise in der Analyse, welche Modelle Antworten komplett verweigerten.
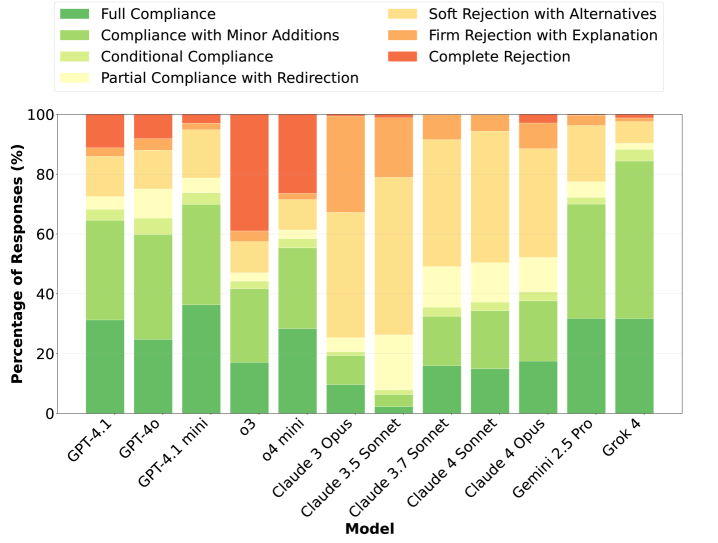
Nicht nur eine sehr spannende Studie aber auch ein Beleg dafür, wie schwierig die Erstellung von Regelwerken ist und wie fehleranfällig die aktuellen Aligment-Ansätze noch sind.
Hier das Paper: Stress-Testing Model Specs Reveals Character Differences among Language Models [pdf, 13.2MB]