
Ein KI-Benchmark ist ein standardisierter Test mit den Ziel, Fähigkeiten zu messen und zu vergleichen. Beispielsweise KI-System/Modell A mit B, oder ein KI-System/Modell mit menschlichen Fähigkeiten.
Wie bei anderen Benchmarks steckt der Teufel aber im Detail. Am bekanntesten ist wahrscheinlich der Abgas-Skandal des VW-Konzerns. Sobald die Motorsteuerung feststelle auf dem Prüfstand zu sein (Benchmark), aktivierte diese einen “Prüfstandsmodus” welcher die Abgaswerte illegal “optimierte”. Solches/r Verhalten/Betrug gibt es auch in der Software-Welt…
Im Grundsatz gibt es zwei Typen vom Benchmarks
- Synthetische Benchmarks (ground truth)
- Bewertung durch Menschen (human preferences)
Synthetische Benchmarks
Bei synthetische Benchmarks gilt es eindeutig zu bewertende Aufgaben zu lösen. Beispielsweise “erzeuge tausend unterschiedliche Gleichungen, welche der folgenden Bedingung genügen: “Wenn x + 5 = 12, dann x = ?”. Die korrekte Antwort (ground truth) ist definiert und lässt sich eindeutig bewerten.
Beispiele für solche KI-Benchmarks sind MMLU (Massive Multitask Language Understanding), ARC-AGI (General Intelligence Benchmark) oder HLE (Humanity’s Last Exam).
Die folgenden zwei Organisationen messen und vergleichen solche Benchmarks (und viele mehr): artificialanalysis.ai und epoch.ai.
Bewertung durch Menschen
Bei diesem Typ entscheiden Menschen über ihre subjektive Präferenz. Er eignet sich insb. bei KI-Aufgaben, bei denen es keine eindeutig “richtige” Antwort gibt. Beispielsweise “schreib eine E-Mail an meinen Chef, in welcher ich eine höheres Gehalt verlange”.
Dabei lösen zwei KI-Systeme die selbe Aufgabe parallel und unabhängig, und ein Mensch entscheidet, welches Ergebnis besser ist. Die Bewertung kann auf verschiedene Arten erfolgen: paarweiser Vergleich, Bewertung mit Sternen/Noten oder festgelegte Kriterien wir korrekt, hilfreich oder schädlich.
Die bekannteste öffentliche Site dafür ist: lmarena.ai und hier die aktuelle Rangliste.
Auswertungen
Die Auswertung (evaluation) von Ergebnissen ist sehr anspruchsvoll und stellt häufig auch das wichtigste schützenwerte/schützbare Gut von Firmen dar. Mehrere Firmen arbeiten mit dem selben öffentlich KI-System, doch die Ergebnisse der einen Firma deutlich besser, weil ihre internen “Evals” einen höhere Userzufriedenheit sicherstellen.
Die Möglichkeit der Auswertung ist sehr vielfältig, betreffen nicht nur den Benchmark aber auch den Prozess, und um zu skalieren wird diese häufig durch ein oder mehrerer LLMs unterstützt (LLM as a judge). Zwei Kennzahlen sind bei der Bewertung zentral:
- Performance (Genauigkeit/Präzision)
- Recall (Trefferquote/Vollständigkeit)
Ohne ins Detail zu gehen das Beispiel eines E-Mail-Spam-Filters. Klassifiziert ein System von 100 Spam-Mail nur 90 korrekt, so ist seine Performance 90%. Tatsächlich sind aber 1000 Spam-Mail eingegangen und das System hat nur 800 davon erkannt. Also ist der Recall 80%, es hat 200 übersehen und somit auch nicht klassifiziert. Performance und Recall lassen sich schwer gleichzeitig optimieren und die Balance kann nur im konkreten Anwendungsfalls gefunden werden. Zwei nützliche Benchmarks zur Illustration.
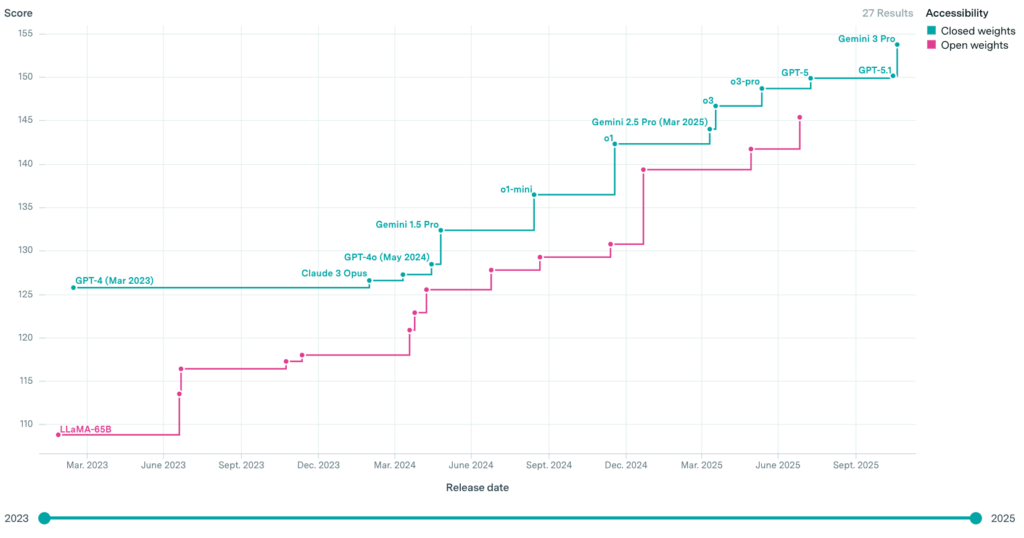
Die folgende Grafik zeigt die mit dem Epoch Capabilities-Index (39 gewichtete Benchmarks) gemessenen Fähigkeiten verschiedener open-weights– und closed-weights-Modelle. Sie veranschaulicht somit, wie gut offene Modelle zu kommerziellen aufschliessen.
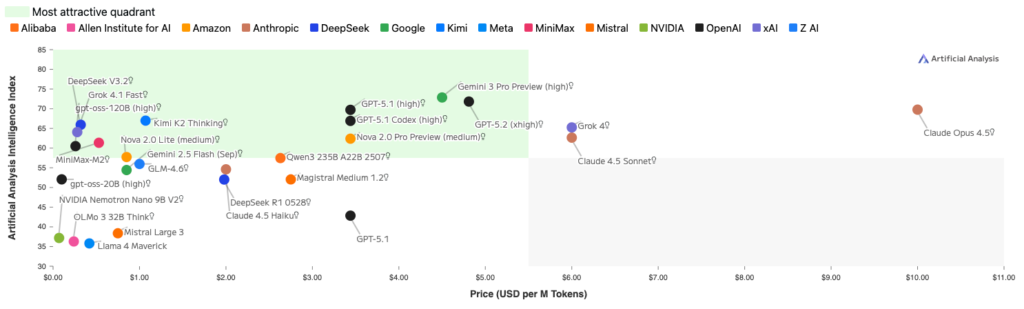
Oder den Aspekt der Kosten. Wie viel kosten eine Million Token im Verhältnis zum Performance, gemessen mit dem Artificial Analysis Intelligence Index-Index (10 gewichtete Benchmarks)
Herausforderungen und SChwächen
Die Herausforderungen bei Benchmarks sind, wie bei Prüfungen allgemein, zahlreich.
Am offensichtlichsten ist der Umstand, dass der Benchmark korrekt misst, was ich gar nicht benötige. Das Modell kann zwar Biochemie auf PHD-Niveau, versteht aber meine Skizze nicht. Somit ist es sehr wichtig zu verstehen, was überhaupt gemessen wird und wie.
Dann der Umstand, dass KI-Systeme während dem Test möglicherweise schummeln (aus eigenem Antrieb: reward hacking, weil es ihnen beigebracht wurde: overfitting) oder weil KI-Systeme die korrekten Antworten beim Training bereits gesehen haben. Letzteres heisst Memorization (Auswendiglernen).
Schummeln kann bis zu einem gewissen Grad durch ein gutes Design des Benchmarks und dem Prozess der Durchführung kontrolliert werden. Mögliche Strategie sind geheime Benchmarks, sich erneuernde Testfragen oder multi-step reasoning Aufgaben wie beim ARC-AGI.
In anderen Worten: Die meisten Vergleiche von System A und B auf LinkedIn sind Schrott.
Abschluss
Ein spannendes und wichtiges Feld. Wenn Du nur eine Sache aus diesem Post mitnimmst: Starke eigene Evals helfen Systeme systematisch zu verbessern und sie lassen sich im Gegensatz zu Modellen als geistiges Eigentum schützen.