
Die Begriffe offen und souverän haben Konjunktur. Doch was sind offene LLMs genau? Zuallererst aber zur Frage, weshalb man offene (Sprach)modelle überhaupt haben möchte? Die wichtigsten Beweggründe dafür findet man in der Open Source Bewegung, der Gesetzgebung und in der Geopolitik.
Beweggründe für offen
Ein mutmasslicher Grund für offene Modelle sind Lizenzkosten und -bedingungen, doch das greift zu kurz, denn Open-Source-Modelle dürfen Geld verlangen, deren Betrieb ist (auch) kostenintensiv und zum Teil sind Open-Source-Lizenzen anspruchsvoll in der Umsetzung. Beispielsweise wegen Haftung, oder wenn Weiterentwicklungen derselben Lizenz unterstellt werden müssen. Ein viel wichtigerer Beweggrund für Open Source ist aber der Aspekt der Innovation und die Qualität von offenen Systemen, da Weiterentwicklungen und Korrekturen rasch und bedingungslos umgesetzt werden können. Dazu kommt der positive Einfluss von Transparenz auf die Sicherheit (no security through obscurity), dazu gleich mehr.
Das zweite Feld an Beweggründen sind gesetzliche Regulierungen mit dem Ziel, Risiken von KI zu reduzieren. So ist die Transparenz der Trainings-, Test- und Validierungsdaten eine zentrale Forderung des EU AI Acts im Artikel 50. Zudem verlangt Artikel 53.1(d) für general-purpose AI: “draw up and make publicly available a sufficiently detailed summary about the content used for training…“.
Und schliesslich die Geopolitik. Der bewusste Fokus von China auf offen und darauf folgend dem Aufbau eines Open-Source-Ökosystems ist im 14. Fünfjahresplan 2021 – 2025 explizit genannt. Es ist der effektivste Weg um Exportbeschränkungen zu umgehen und mit der weltweiten Forschungscommunity zusammenzuarbeiten.
Doch was heisst offen genau?
Open-weights versus Open Source
In den allermeisten Fällen wird bei einem “offenen LLM” nur die Modellgewichte veröffentlicht. Korrekterweise müsste man also von “open-weigths Modell” sprechen. Das heisst, ich kann das Modell nutzen und, je nach Bereitstellung und Lizenz, auch verändern. Was ich aber nicht kann, ist es nachzubauen weil mir dazu die Grundlagen fehlen. Oder in anderen Worten: Ich kann nicht nachvollziehen, was im Modell drin steckt. Dafür bräuchte ich ein (echtes) Open-Source-LLM inklusive allen Daten, Rezepten und Methoden.
In Bezug auf die oben genannten Bewegründe sind open-weigths LLMs ein Problem, denn die Transparenzverpflichtungen des EU AI Acts sind nicht erfüllt. Und auch weitere gesetzliche Anforderungen an Trainingsdaten, beispielsweise im Rahmen des Urheberrechts, können nicht garantiert werden.
Zudem lässt ich auch die Sicherheit und Qualität der Modelle nicht verifizieren und, wegen den fehlenden Elementen des Herstellungsprozesse, auch nicht ursächlich verbessern. Sicherheit und Qualität beginnt so wie bei so wie auch bei Software-Qualität auch hier beim ersten Token der Herstellung und nicht im Post-Training.
Zwei Ansätze zur Übersicht
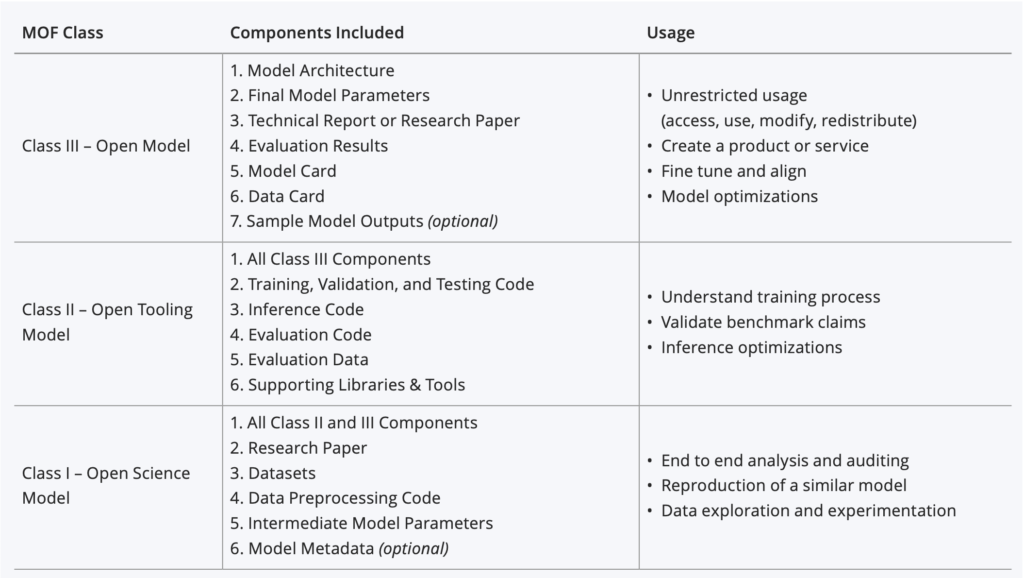
Die Linux Foundation hat mit dem Model Openness Framework (MOF) eine Spezifikation vorgeschlagen, welche die Offenheit von LLMs basierend auf 16 Fragen in drei Stufen einteilt. Open Model, Open Tooling Model und Open Science Model.
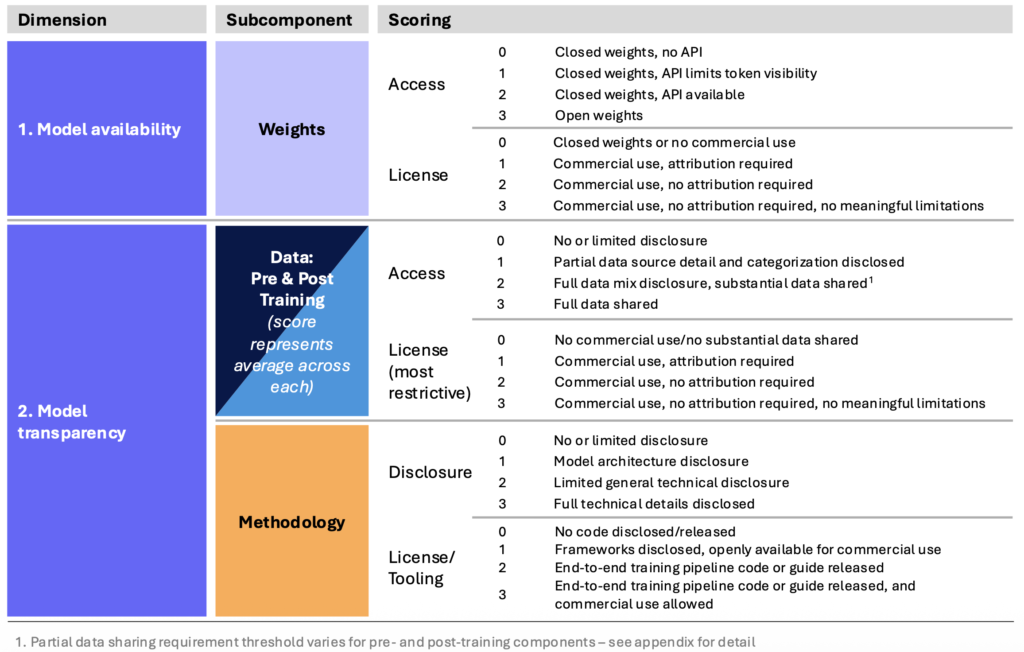
Dank gut gemachter Darstellung und Verknüpfung finde ich den Artificial Analysis Openness Index von der Benchmarking-Platform Artificial Intelligence zugänglicher. Der Index bewertet die folgenden Elemente.
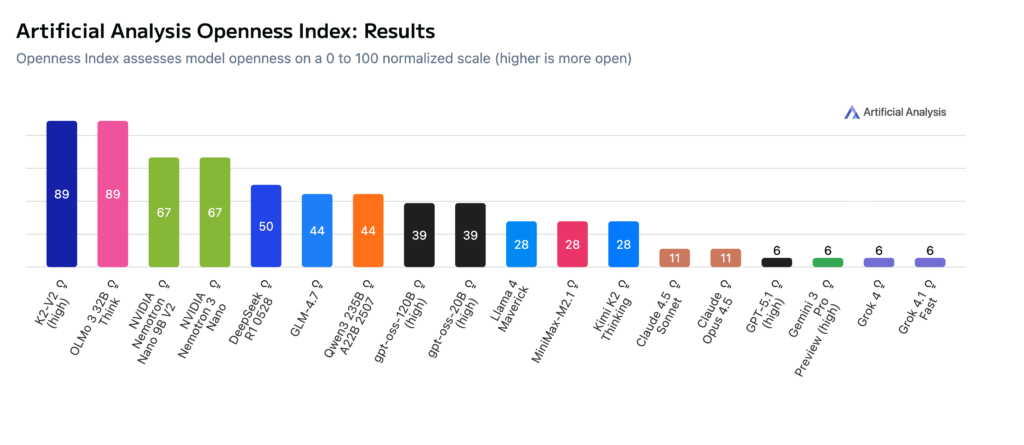
Ganz oben auf der Rangliste ist K2-V2 von der Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) und OLMo von Ai2 (Allen Institute for Artificial Intelligence). Leider wurde Apertus von Swiss AI noch nicht berücksichtigt, doch es wäre auch ganz oben vertreten.
Update 5. Jan 26. Aufgrund eines Kommentars von Lars Riedemann, Co-Autor der Studie “The path forward for large language models in medicine is open”, wurde ich noch auf European Open Source AI Index aufmerksam. Dieser bewertet auch Apertus und rangiert es im Bezug auf Offenheit gleich wie OLMo.
Abschluss
Offen heisst nicht offen. Ist mir nicht nur der eigene Betrieb (was open-weights erlaubt) wichtig, möchte ich aber auch rechtliche Rahmenbedingungen berücksichtigen, so führt keinen Weg an offenen Modellen, so wie es die oben genannten Ansätze beschreiben, vorbei.
Ist mir zudem Sicherkeit und Erklärbarkeit wichtig, so muss ich mich mit Open Source Modellen beschäftigen. Raymond’s Mantra gilt auch hier: Given enough eyeballs, all bugs are shallow.