
There are many reasons why I don’t want data to be fed into the training of large language models (LLMs). In this post, I will focus on hiding benchmark and study content to maintain the quality of LLM analysis results.
The challenges
If LLMs see the results of benchmark questions (or study results) during pretraining, future benchmarking or analysis results will be affected by this. In the case of a benchmark, we would not be able to measure the ability of a system to answer a question, but rather how well the system can find a memorized answer within its model.
In the case of studies — take security issues, for example — the result of an LLM being aware of the content could be much worse. Understanding certain behaviors and proposed solutions could enable models to learn how to trick humans about what they want the models to refrain from.
A melodious bird called canary
A proposed approach to exclude assets from training is to place an instruction in the content I don’t want to be used. The crawler gathering training content or the preprocessor preparing for machine learning (pretraining data filtering) can detect this instruction and voluntarily exclude the text. Here an example of a footer in a study by Anthropic about reward hacking.

The term “canary” comes from coal miners who placed canaries into coal mines as an early-warning signal for toxic gases, primarily carbon monoxide. If the bird died, there was a problem. Somehow programmers adopted this for example to detect buffer overflows on stack-allocated variables or programs overwriting security-critical sections in memory.
The logic behind
The sequence above is a random number and is technically called a GUID (globally unique identifier). Once created and if everybody agreed on it, its used as an identifier for content to be excluded from training. They way its crafted, it should never occur in normal text.
As you can imagine this only works, if all the model makers agree on the principle and the sequence. A quick search reveals additional initiatives. Here is a comment in the code repository of the study Alignment faking in large language models.
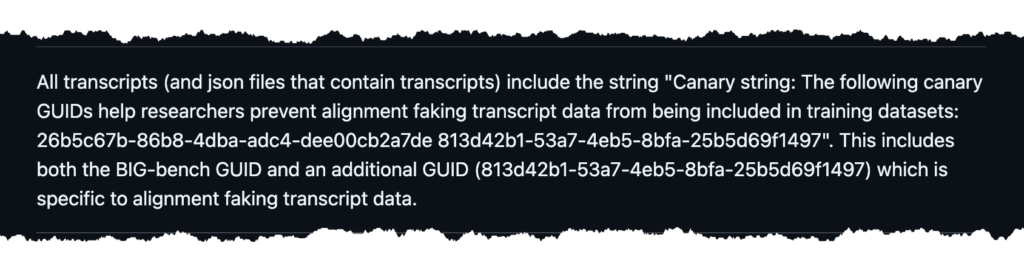
The sequence starting with 26b5 is called “BIG-Bench canary string” and you will find many comments about models that did not exclude it in pretraining. Content containing the string showed up in GPT-4, Opus 3, and Sonnet 3.5. And its also reproduced by two more frontier models: Gemini 3 Pro and Claude Opus 4.5.
Summary
As with many things in artificial intelligence, this approach looks more like a prototype than a solution. Especially because it’s very easy to misuse (could I exclude my own content like this?) and there is no transparency about who follows the rule.