
Vor Jahren verneinte ich die Frage eines Entwicklers, ob Software sich je selbst schreiben könne. Heute ist es Realität. KI-Systeme wie Claude Code oder Codex CLI entwickeln selbständig anspruchsvollen Programm-Code.
Wirklich? Im Folgenden ein Einblick in zwei spannende Artikel von Anthropic (Building a C compiler with a team of parallel Claudes) und Open AI (Harness engineering: leveraging Codex in an agent-first world). Und die Antwort ist: Ja, wirklich.
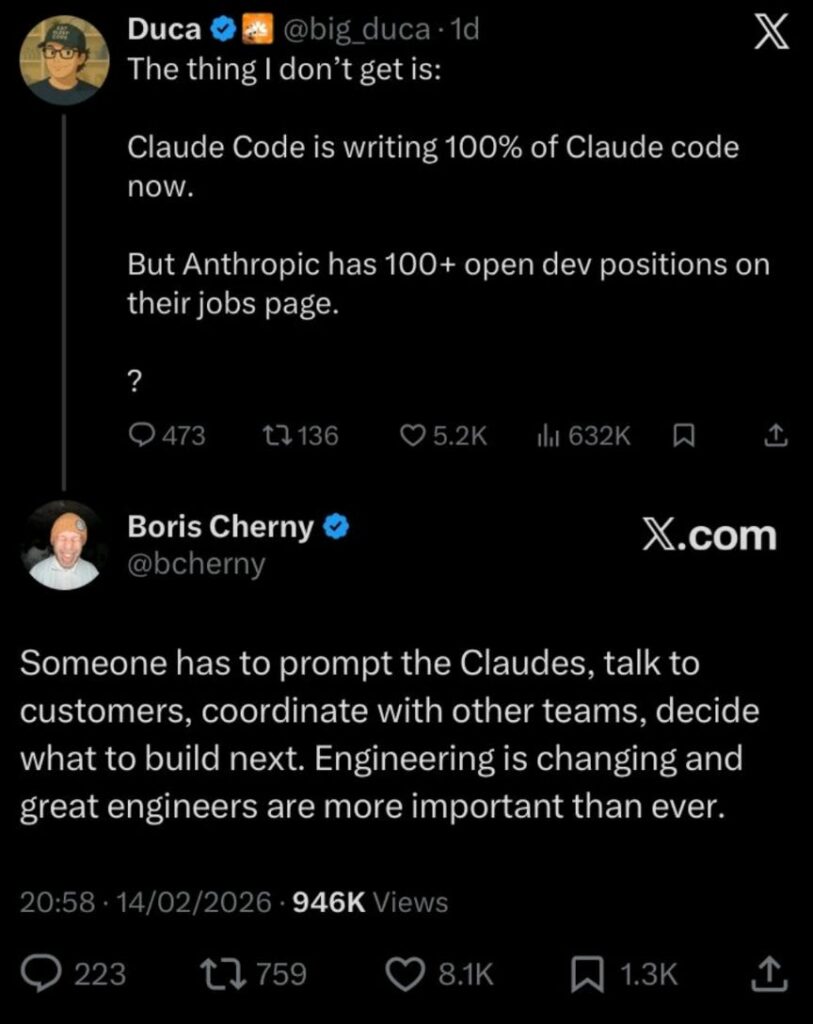
Und weshalb sucht Anthropic Programmierer?
Die Jobs fallen nicht weg, sie wandeln sich aber in einer sehr hohen Geschwindigkeit. Hier in den Worten des Lead-Entwicklers von Claude Code, Boris Cherny.
Experiment 1: C Compiler
Das Experiment fühlt sich also ein wenig an, als ob ein Werkzeugbauer sein eigenes Werkzeug herstellt. So war auch die «Definition of Done»: Das Experiment ist abgeschlossen, wenn der neu erstellte C Compiler den Linux Kernel übersetzen kann. Hier übrigens das Ergebnis auf GitHub.
Der von Claude Code geschrieben C Compiler umfasst rund 100’000 Zeilen Code. Das Team von bis zu 16 Agenten basierend auf dem Modell Opus 4.6 hat dabei rund 2 Mia. Input Tokens gebraucht. Dies entspricht (Inferenz-)Kosten von rund USD 20’000.
Experiment 2: Beta-Version eines Software-Produkts
Das Experiment von Open AI ist weniger transparent dokumentiert. Ihr Ziel war explizit «0 lines of manually-written code». Das Projekt startete im August 2025, nutzte Codex CLI mit GPT‑5 und erzeugte rund 1 Mio. Zeilen Code aufgeteilt in 1’500 pull requests, welche von einem Team von drei Leuten zusammengeführt werden (was für ein Job).
Die wichtigsten Erkenntnisse
Zwei unterschiedliche Experimente, die Erkenntnisse sind aber fast identisch.
- Depth-first
- Extrem hochwertige, automatisierte Tests
- Kontext Management
- Synchronisation und Zeitblindheit
Wenn man die Systeme „einfach mal laufen lässt”, entsteht nicht nur nichts Brauchbares, sondern die minderwertigen Ansätze werden durch die Agenten automatisch vervielfältigt. Die Lösung ist eine sehr sorgfältige (depth-first) Dokumentation von Prinzipien. Mikromanagement funktioniert nicht und Illustrationen (maps) funktionieren besser als langfädige Dokumente.
Zu Beginn versuchte das Team von Open AI jeden Freitag «AI slop» zu entfernen, Ohne Erfolg, da die Agenten schneller waren ;). Der Ansatz in beiden Experimenten sind sehr elaborierte Test und Testumgebungen mit Zugriff auf den Prozess von Deployment bis User Agent mit allen Zugriffen und Log-Dateien. Alles muss messbar und für die Agenten zugänglich sein.
Das Kontextmanagement ist eine der grössten Herausforderungen, da jede Session eines Agenten in einem leeren Container startet und sich zuerst einarbeiten muss. Zudem ist zu viel Kontext kein Kontext und der relevante Kontext muss zugänglich sein (nicht in einem Chat). Der ganze Kontext muss ins Repository und das Kontextfenster muss «sauber» gehalten werden. Ein erfolgreicher Ansatz dazu war die schrittweise Offenlegung von Kontext und Nutzung von AGENTS.md (mit nur 100 Zeilen) als Inhaltsverzeichnis mit Verweisen auf weitere Dateien.
Arbeiten ein Dutzend Agenten gleichzeitig, so ist deren Arbeitsaufteilung in zeitlicher Hinsicht ein Problem. Zudem haben die Agenten kein Zeitgefühl, beispielsweise um einen Job abzubrechen oder um die Möglichkeit einer Synchronisation zu suchen. Das Paper von Anthropic beschreibt ihren Lösungsansatz dazu.
Abschluss
Das Allermeiste, das ich gelesen habe, erinnert mich an die Einarbeitung unerfahrener Mitarbeiter:innen und an klassische Führungsaufgaben. Irgendwie alles logisch, aber auch ziemlich spannenden in Bezug auf grad neu entstehenden Rollen.