

Unter dem Titel «Generating Trillions of the Finest Tokens» dokumentiert Hugging Face ein grossangelegtes Experiment zu synthetischen Daten. Aber zuerst zur Frage, weshalb es synthetische Daten überhaupt braucht?
Die Datenquelle Internet ist ausgetrocknet
Frühe Sprachmodelle wurden mit Quellen wie Wikipedia (ca. 7 GB) oder dem Projekt Gutenberg (ca. 12 GB) trainiert. Doch rasch wurde alles, was das Internet zu bieten hat, hinzugezogen (unabhängig von Urheber- und Nutzungsrechten). Als grosse Kollektionen galten im Jahr 2020 The Pile (886 GB, 1.35 Billionen Token) und im Jahr 2024 FineWeb (45’000 GB, 15 Billionen Token).
Mit dem Ziel grössere Modelle zu trainieren wollte man mehr Daten, doch die (einigermassen) legalen Quellen waren schon genutzt. Einige Firmen machten sich an private Daten und andere fokussierten sich auf Datenqualität. Bei dem letzten Punkt kommen synthetische Daten ins Spiel.
Was sind synthetische Daten?
Einen Weg um die Datenqualität zu erhöhen, ist das Entfernen unerwünschter Daten -— beispielweise indem man Duplikate und Similikate identifiziert und löscht bzw. unerwünschte/toxische Daten entfernt. Problem dabei ist es, dass die Datenmenge bald schneller schrumpft als der Nutzen steigt und dass Diversität von Trainigsdaten einen positiveren Einfluss hat als deren Konsistenz.
Willkommen in der Welt der Generierung von synthetischen Daten: Man nehme bestehende Daten und erweitert diese mit Hilfe eines LLMs. Beispielsweise indem man einen Artikel aus Wikipedia in unterschiedliche Formate umformuliert. Doch dazu später mehr.
Ein Beispiel hierfür ist das Unternehmen Z.ai, das im Rahmen der Erstellung seines Modell GLM-4.5 rund 500 Milliarden Token erzeugt haben.
Und was ist mit « model collapse» (Modelltraining auf rekursiv generierten Daten)?
Intuitiv meint man, dass synthetische Daten zu einem Problem werden, da irgendwann rekursiv trainiert wird. Dies wurde Mitte 2024 auch in «AI models collapse when trained on recursively generated data» dargelegt, einer Studie welche Modelle ausschliesslich mit selbst erzeugten Daten trainiert hat.
Die Arbeit von Hugging Face geht direkt auf diese Studie ein und zwar mit der Aussage: In practice, nobody trains models this way. Synthetische Daten dienen immer der Beimischung zu resp. der Umformulierung von hochwertigen, validierten Daten.
Wie funktioniert die Erzeugung synthetischer Daten?
Genau zu dieser Frage hat das erwähnte Paper von Hugging Face 90 Experimente durchgeführt, über eine Billion Token verarbeitet und über 100’000 GPU-Rechenstunden investiert. Ergebnis davon ist eine detaillierte Anweisung, ein Synthetic Data Playbook. Die Experimente wurden entlang den folgenden Dimensionen geplant
- Welche Art der Reformulierung von Daten (rephrasing) erhöht die Performance beim nachfolgenden Training?
- Welche Modelleigenschaften wirken sich positiv auf die Generierung aus?
- Welchen Einfluss hat die Qualität der Ausgangsdaten?
Die folgende Grafik zeigt links die Ausgangsdaten, in der Mitte die Art der Reformulierung und rechts das dazu genutzte Modell. Die Breite der Verbindungen zeigen die Anzahl der ausgeführten Dokumente in der entsprechenden Kombination.
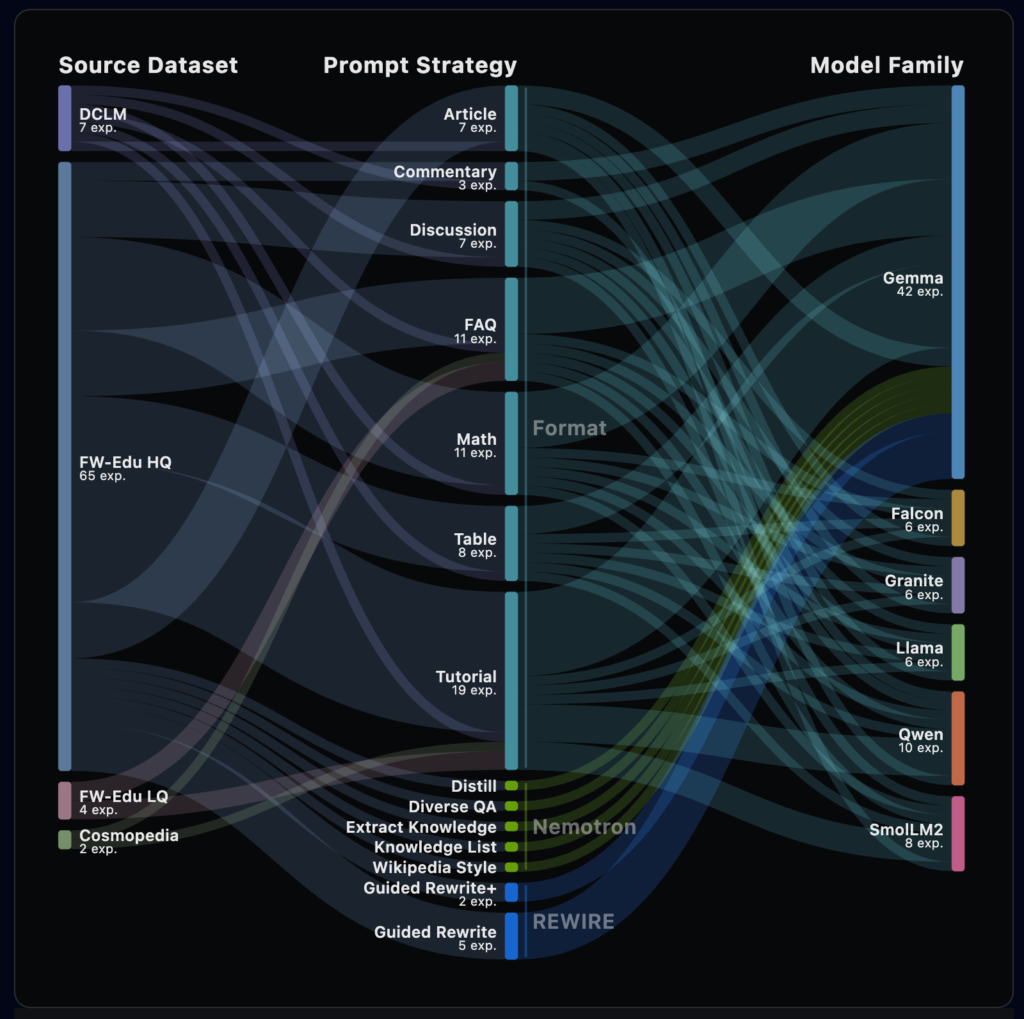
Art der Reformulierung
Bei der Reformulierung wird ein Ausgangsdatensatz genommen und mittels einen LLM in andere Formate umgeschrieben. Beispielsweise nimmt man einen Aufsatz und erstellt daraus zusätzlich ein Tutorial, einen Wikipedia Artikel, einen Kommentar, eine Diskussion, eine Tabelle und ein FAQ Dokument. Aus eins mach sieben.
Gemessen gegen das qualitativ hochwertige DCLM Datensatz brachten die Formate FAQ, MATH, TABLE und TUTORIAL eine Verbesserung. Alle anderen Formate verschlechtern die Performance. Konkret: Man nehme einen Datensatz, ein geeignetes Modell (siehe unten) und den folgenden Prompt. Das Ergebnis wird den Trainingsdaten zugefügt und verbessert (wegen der Reformulierung) die Performance des in der Folge trainierten Modells.
Rewrite the document as a comprehensive FAQ (Frequently Asked Questions). Extract or infer the key questions a reader would have about this topic, then provide clear, direct answers. Order questions logically—from foundational to advanced, or by topic area. Each answer should be self-contained and understandable without reference to other answers. Ensure the FAQ works as a standalone document. Output only the FAQ, nothing else.Modelleigenschaften
Weiter testeten die Autoren unterschiedliche Modellfamilien, -generationen und -grössen. Neben offensichtlichen Erkenntnissen, stellten sie auch fest, dass grössere Modelle das Ergebnis gegenüber dem DCLM-Benchmark verschlechtern. So zeigt die folgende Grafik jeweils das Gemma-3-1B und Gemma-3-12B beim oben gezeigten FAQ Task auf zwei unterschiedlichen Ausgangsdaten. Das kleinere Modell schlägt das grössere Modell.
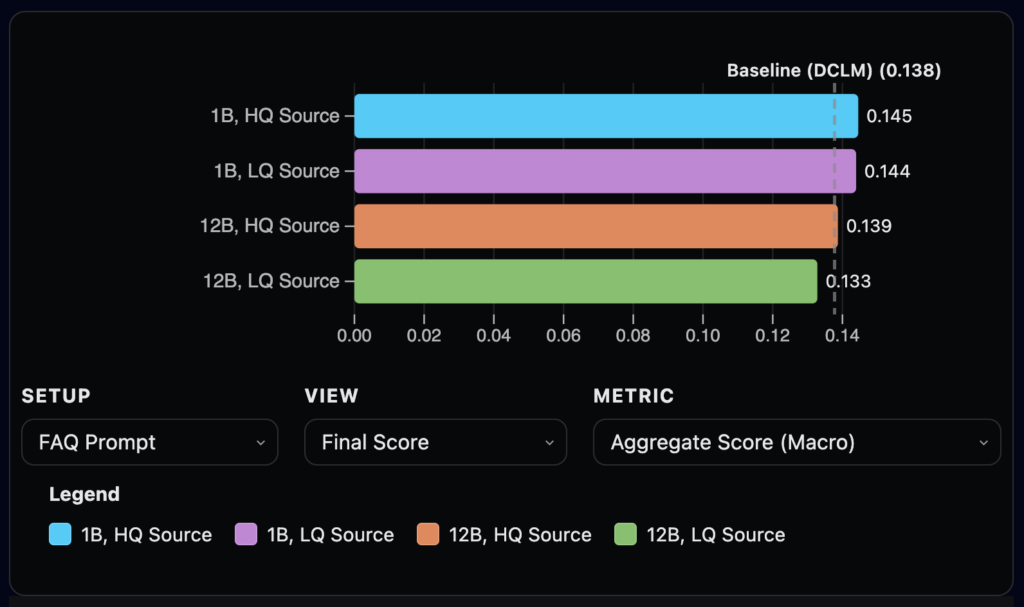
Qualität der Ausgangsdaten
Um ungewünschte Muster in den Ausgangsdaten nicht zu verstärken oder während dem Training gewisse Eigenschaften zu erlernen resp. zu verstärken, werden sogenannte mix-in Datensets ergänzt. In den Experimenten wurde – zum Erstaunen der Autoren – festgestellt, dass die Wahl des mix-in Datensets in ihrem Setup einen grösseren Einfluss hatte als die Ausgangsdaten. Der Effekt war bei schwächeren Ausgangsdaten sogar noch deutlicher: This is exciting: it means you can rephrase even low-quality data and still get competitive results, as long as you pair it with a strong mix-in dataset.
Abschluss
Ziel war es den Schleier über (und auch Falschaussagen zu) synthetischen Daten zu lüften. Dies, da deren Wichtigkeit massiv zunehmen wird. Ein spannender Artikel dazu findet sich beim WEF: «We’re running low on data to train AI. The good news is there’s a fix for that».
Auch gut illustrieren die Experimente, dass grösser nicht immer besser ist. Weder in Bezug auf Kosten noch in Bezug auf die Performance. Bei den getesteten Aufgaben haben die 1B Modelle ihre riesigen Nachbarn systematisch geschlagen.
Zudem bietet die exzellent aufgearbeitete Studie sehr viele spannende Aussagen zu Infrastruktur, Architektur und Kosten(optimierung) beim Training von Modellen.
Etwas vom Besten, das ich seit langem gelesen habe: The Synthetic Data Playbook: Generating Trillions of the Finest Tokens, hier auch als PDF 5.5 MB.