
Im Rahmen des Google Developer Day sprach Peter Norvig über “Theorizing from Data”.
Dabei geht es im Kern um einen alten Streit zwischen Linguisten und Statistiker, der Norvig sehr elegant zu Gunsten der Statistiker entscheidet: “If you don’t have the data, you don’t do progress”.
Nach einer Einführung, weshalb der bei Google arbeitet (“because that’s where the data is”), zitiert er ein Paper von Banko und Brill, in welchem sie empirisch zeigen, dass der beim einem Trainigsset von 1 Mio. Dokumenten der schlechteste Algorithmus zur Disambiguierung von Worten den besten (immer bei 1 Mio.) schlägt, sobald dieser mit 10 Mio. trainiert ist. Der Einfluss der Daten ist also wichtiger als der Unterschied der Berechnung.
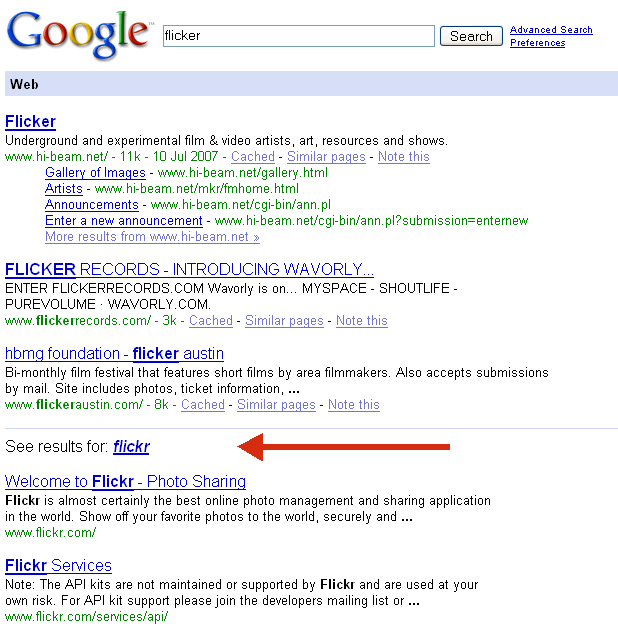
Nun beginnt er mit Beispielen, welche auf einem englischen Korpus von Google basieren den sie aus dem Web Crawl für das LDC erstellt haben. Darin finden sich 95 Mio. Sätze mit 13 Mio. unterschiedlichen Worten (inkl. Zahlen, Eigennamen und Tippfehlern). Damit macht Google beispielsweise Query Refinment. Hier beim Term “flicker” (mit e) und einiges mehr.
Norvig beginnt nun in seinem Trainingsset mit “unsupervised machine reading” Konzepte zu clustern (z.B. company, industry, business). Dann sucht der nach Relationen (z.B. {Konzept} complained to {Konzept} about) und schlussendlich abgeleitete Muster X complained to Y about Z == x filed a complained about Z with/to Y == a complaint to X about Z u.s.w. Wohlgemerkt ohne linguistisches Wissen aber nur über Statistik. Und immer wieder Seitenhiebe gegen die Lingusten mit empirischen Erkenntnissen die halt einfach richtig sind 😉 So beispielsweise führt er Stemming ad absurdum, indem er zeigt, dass eine Konkatenierung nach 4 Zeichen ein bessere Resultat bringt (dabei wollten sie nur Platz sparen 😉
Und kaum dreht man sich um, zeigt Norvig statistische Übersetzungen die, zumindest in der ausgewählten Beispielen, sehr gute Resultate bringen. Dies Dank der schieren Menge an Trainingsdaten. Für alle, die ein bisschen Spass an Statistik (und oder Liguistik) haben ein brillianter Vortrag. Und hier noch ein Bild wegen der Bemerkung wegen dem Hemd.

PS: Für Leute die sich schon immer fragten, wie ich YouTube Video runterladen kann. Hier ein Dienst und ein benötigter FLV-Player.
Look at the Data (not at the Shirt)
L
Ein Dienst zum Konvertieren von diversen Formaten (u.a. FLV) ist auf http://media-convert.com/konvertieren/
Ein Player ist VLC: http://www.videolan.org/vlc/