
Nach einem ersten Teil “Search Analytics – Kennzahlen um die Query”, hier der zweite Streich. Ziel ist es weiterhin die Effektivität der Suche (“Suchmaschine”) faktenbasiert zu verbessern. Also nicht ein Zaub(d)erer, der mit viel warmer Luft erklärt was zu tun ist, niemand ihm folgen kann und nach der Änderung immer noch alle unglücklich sind aber: Zahlen. Das ganze ist ein Teil von Web Analytics: Der Erfolgsmessung im Internet. Erlauben Sie zuerst die folgende Erklärung.
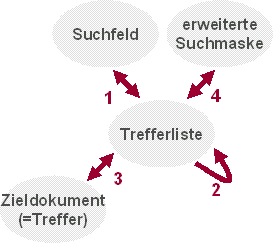
Die Ellipsen zeigen typische Zustände (“Seiten”) einer Suchanwendung. Das Suchfeld (mit sehr wenigen Optionen beispielsweise auf jeder Seite rechts oben), die erweitere Suchmaske (mit allen Optionen), die Trefferliste (gerne auch mit SERP = Search Engine Result Page abgekürzt) und das Zieldokument (das in der Trefferliste verlinkte Ziel).
Alle Übergänge sind im Rahmen der Navigation möglich. So zum Beispiel gebe ich im Suchfeld einen Begriff ein und lande (nach dem Klick auf dem “Suchen”-Button über Pfeil 1 auf der Trefferliste. Dort blättere ich eine Seite, da ich in den Zitaten das Gesuchte nicht zu finden meine (über Pfeil 2) und schlussendlich wähle ich einen Eintrag der zweiten Trefferliste und lande über Pfeil 3 auf dem Zieldokument. Viele andere Wege sind möglich: Von der Trefferliste zurück zum Suchfeld, vom Zieldokument zurück zur Trefferliste etc. Und nun zu den Zahlen:
1. Auswahlhäufigkeit (Selection Ration)
2. Suchabbruch (Search Abandonment)
3. durchschnittliche Ranglistenposition gelickter Treffer
4. in der Trefferliste geklickte URLs
5. aufrufende Seite
Auch hier wieder gehören die Werte wieder zyklisch ausgewertet etc.
zu 1) Die Auswahlhäufigkeit ist die Anzahl der Suchanfragen, bei denen User in der Trefferliste auf mindestens einen Treffer klicken geteilt durch die Anzahl der Suchanfragen. Führt ein User eine Suche aus und klickt auf einen Treffer der Trefferliste, so steht die (statistische) Chance gut, dass er fündig wurde. Das Verhältnis ist 1. Bei einem kleineren Verhältnis führt der User mehrere Suchanfragen aus, klickt aber weniger Treffer. Dies ist ein Hinweis, dass das Gesuchte nicht im Index ist (gar nicht auf der Trefferliste erscheint), die Rangierung schlecht ist oder das Trefferzitat eines relevanten Eintrags nicht zu einem Klick verleitet. Und ist die Auswahlhäufigkeit grösser Eins, so wählt der User zu wenig Suchanfragen sehr viele Kandidaten für einen Treffer, kommt aber immer wieder zur Suche zurück, da das gewählte Zieldokument sein Informationsbedürfnis nicht befriedigt hat.
zu 2) Der Suchabbruch ist der Fall, bei dem User nach einer Suche auf null Treffer klicken. Die Kennzahl das Verhältnis der Abbrüche zur Anzahl Suchanfragen. Um dies festzustellen, muss ein geeignetes Zeitintervall festgelegt werden, wie lange ein einzelner Suchprozess (Session) maximal dauern darf. Bspw. 5 Minuten. Eine gute Kennzahl ist möglichst tief.
zu 3) Die durchschnittliche Ranglistenpposition ist eine Aussage zur Rankingqualität aus Usersicht und erlaubt, je nachdem ob die Trefferliste immer gleich lang ist resp. die Anzahl Einträge pro Rangliste im Tracking bekannt sind, auch die Berechnung wie häufig zwischen Ranglisten geblättert wird. In der oberen Graphik ist dies der Übergang 2 und eine tiefe Kennzahl nahe bei 1 (der gelickte Treffer ist immer auf Rang 1) ist optimal.
zu 4) Die in der Rangliste geklickte URLs ist keine Kennzahl, dennoch eine wertvolle Aussage. Sozusagen eine BottomUp-Sicht darauf, welche Zielseiten regelmässig über die Suche gefunden werden. Diese Seiten sind Kandidaten für eine höher Gewichtung in der Informationsarchitektur (“ab auf die Hompage”), aber auch Kandidaten für hervorgehobene Top Treffer in der Rangliste. Achten Sie hier auf die Saisonalität der Suchanfragen.
zu 5) Auch keine Kennzahl. Die Seiten, aber welcher die Trefferliste aufgerufen wurde (der Referrer). Haben Sie beispielsweise auf jeder Seite oben rechts ein Suchfeld, so kann der Ursprung der Suchanfrage ganz unterschiedlich sein. Stellen Sie beispielsweise fest, dass regelmässig im Bereich der Pressemitteilungen gesucht wird (die per Zufall leider alle als PDF angebiten werden). Diese Erkenntnis ist auch Grundlage für Gewichtung von Inhalten und für spezialisierte Suchfunktionen.
Soweit so gut. Für Frage und Bemerkungen bin ich gerne zu haben und es folgt noch ein dritter Teil über Kennzahlen um den Suchindex.
PS: Dieser Post ist Teil der dreiteiligen Serie Search Analytics.
Search Analytics – Kennzahlen um die Trefferliste (Teil 2)
S