
The same wisdom again, but this time illustrated by (and mitigated with) AI: Humans don’t scale.
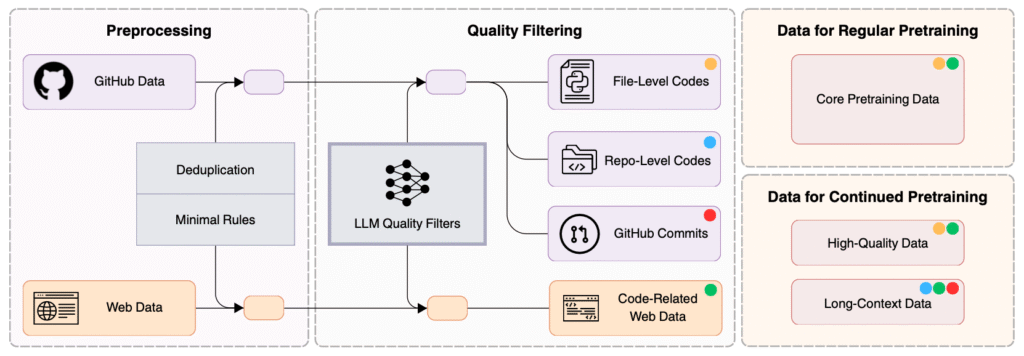
With Seed-Coder, the people from ByteDance just released a family of LLMs focused on the generation of code. Aside an excellent performance and an open-source approach, they highlight their curation process of data used for pretraining. In short, LLMs played a central role in filtering and curating data instead of relying on human effort.
Very prominently, they reference the article “The Bitter Lesson” by Rich Sutton that draws a parallel of growth in compute (Moore’s law) with advances in Ai research. This said, he advises researchers to invest in leveraging computation and not rely too much on human knowledge of a domain. The bitter lesson for him is that to much human knowledge only helps n the short run, but ultimately leads to plateaus and even inhibits further progress. Or in other words: Human knowledge and intuition scale less well than number crunching.
A prominent reference in their paper is Rich Sutton’s article “The Bitter Lesson”, which draws a parallel between the growth of computing power (Moore’s Law) and the progress of AI research. He advises researchers to invest in the use of computation and not to rely too much on human knowledge of a domain. The bitter lesson for him is that too much human knowledge helps in the short term, but ultimately leads to plateaus and even inhibits further progress. In other words: Human knowledge and intuition do not scale as well as number crunching.
In the paper “Seed-Coder: Let the Code Model Curate Data for Itself” this is nicely illustrated by comparing rule-based and LLM-based filters. An example are two code snippets, where the LLM selected the one excluded by (man made) rules (subjective biases, limited in scalability, and costly to extend and maintain) and correctly excluded the one which passed he filter.
- Left: this Python snippet is incorrectly dropped by rule-based filters due to a high numeric-character ratio. In contrast, LLM filter identifies that the code serves a meaningful purpose: showing a Pikachu image on an LED display.
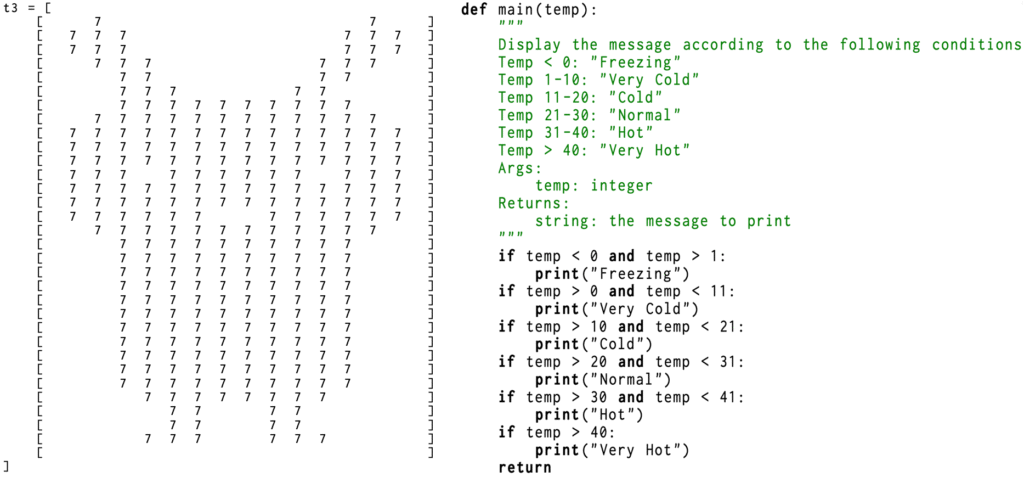
- Right: this visually well-structured Python script passes rule-based filters. However, LLM-based filter identifies logical error (
if temp < 0 and temp > 1) and an inconsistent docstring (it claims to return a string but actually returnsNone), accurately rejecting this low-quality code.
An impressive example of how looking at facts massively improves results.