
Die Frage ist mir in den letzten Tag grad einige Male über den Weg gelaufen. Genügend oft für eine öffentliche Antwort.
Aus welchem Grund auch immer (neue Website, Update Technologie etc.): Ich habe Links in öffentlichen Suchmaschinen, die nicht mehr gültig sind. Währenddem Google+Co. (sorry für die Verallgemeinerung) sehr rasch neue Seiten aufnimmt, werden alte Seiten fast nicht aus dem Index gelöscht. Der Grund ist klar: Der Index wird differenziell erneuert und kaum je komplett geprüft. Dies, weil zu aufwändig und weil es weder einen einzigen Index noch eine einzige Crawl-Quelle gibt (aber viele verteilte).
Die Möglichkeiten wenn ein User eine ungültige URL aufruft und auf meinen Server kommt.
Wenn jemand die Seite nachfragt
1) sendet mein Webserver einen “normalen” HTTP Code 404 (page not found). Da die meisten Suchmaschinen über Browser-Helpers, Deskbar etc. die ganze Surftour tracken merken dass die Maschinen. Unschön für User, da eine Fehlerseite aber die Korrektur der Suchmaschine kommt irgendwann.
2) sendet mein Webserver eine normale HTML-Seite mit einem netten Text “Seite nicht gefunden” und einem HTTP Code 200 (ok). Schlecht für Suchmaschinen, weil diese nicht merkt, dass die URL ungültig ist. Im besten Fall indexiert die Suchmaschinen den Text (weil sie diesen inhaltlich nicht “versteht”).
3) sendet mein Webserver einen HTTP Code 301 (moved permanently) und verweist auf eine gute/bessere Seite. Z.B Sitemap und/oder Suche mit einer Meldung, dass der Link nicht mehr existiert. Nach Aussage von Google ist das ein möglicher Weg. Die Ziel-URL ist aber eine andere, als die aufgerufe und Bookmarks/Links werden evt. nicht angepasst. Also für Menschen nicht ideal.
Der Favorit 4) sendet mein Webserver eine nette Meldung und einer Hilfe zum weitersurfen unter derselben URL z.B. Übersicht über Sitemap und der User wählt aktiv. KEINEN Automatismus mit Weiterleitung, da es Ziel ist, dass Bookmarks geändert werden. Und nun das wichtige Detail: Der Response Code ist HTTP 404 (page not found) UND diese Seite hat den Content Typ text/html (wichtig, sonst zeigt IE eine Fehlerseite) UND diese Seite ist mindestens 512 Bytes gross. Die Seite wird den User normal gezeigt, aber der Suchmaschinencrawler erhält die Information, das die eingehende URL nicht mehr gültig ist. Wenn alles nett programmiert ist, müsste diese somit bald aus dem Index. Ein Beispiel von jemandem, der das so macht: Google selbst:
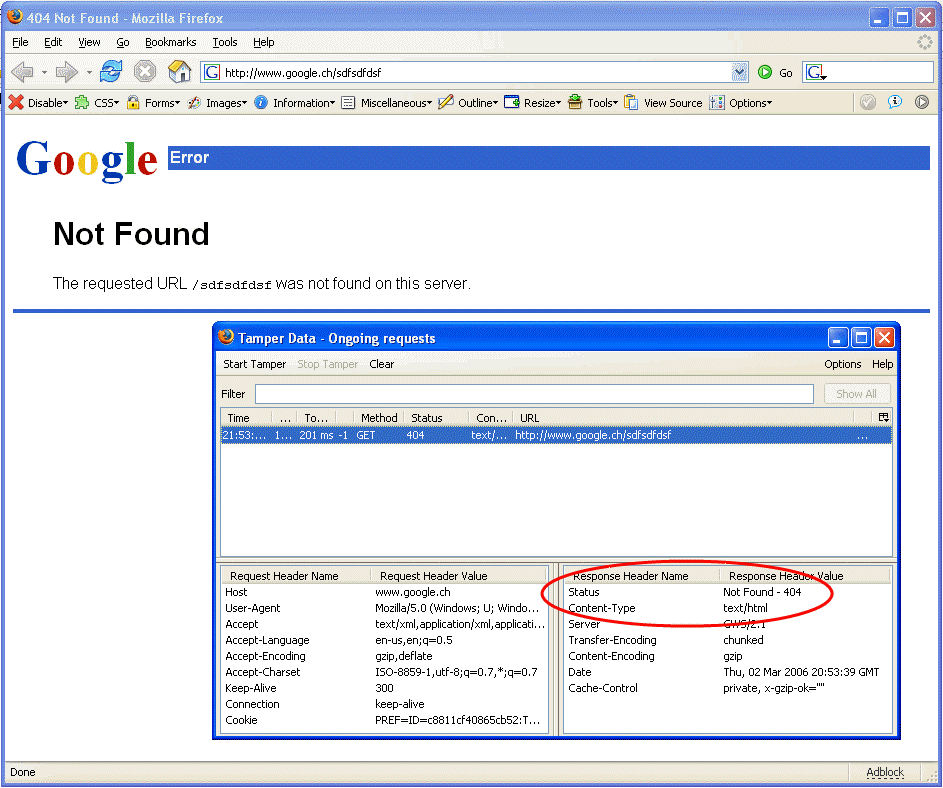
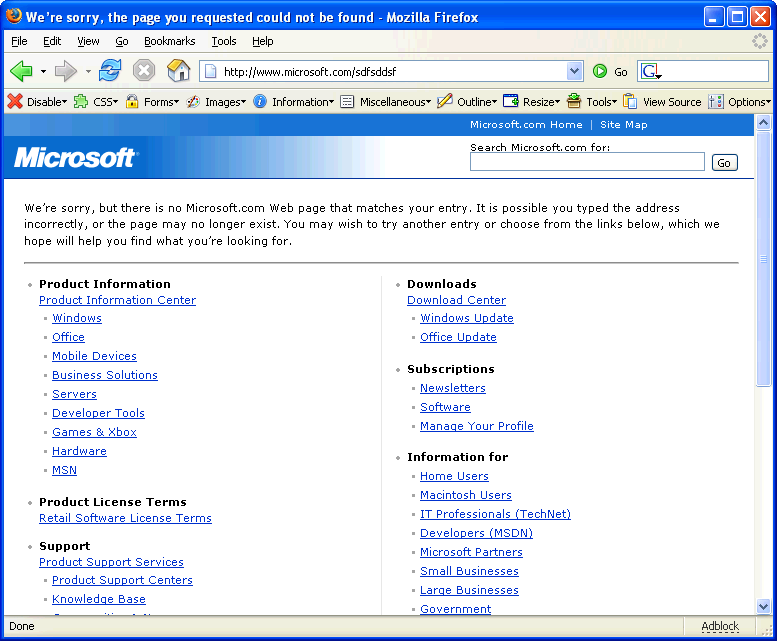
Bezüglich dem User weiterhelfen ist auch Microsoft nicht schlecht (der HTTP Code ist auch hier 404):
5) Nun noch Google spezfisch (wobei alle anderen Suchmaschine auch solche Formulare haben)
5a) Die Seite(n) bei Google von Hand abmelden (mir ist der Automatismus lieber, da es ein Kampf gegen Windmühle ist).
5b) Eine Google Sitemap nur mit gültigen Links raufspielen und zwar regelmässig. Ich bin mir aber unsicher, ob damit die restlichen Seiten der selben Domäne gelöscht werden (eher nicht). Dieser Ansatz ist gut für Shops und andere Sites, die Crawling-Probleme haben.
Was habe ich vergessen?
Wie verschwinden alte Seiten aus dem Suchmaschinenindex
W
Der 404 muss mindestens 512 Byte gross sein, sonst zeigt der IE den Standardfehler an.
Danke für den Hinweis. Wusste ich nicht!
Und leider ist mir keine Möglichkeit bekannt mit Google Sitemaps das ausschliessen von nicht darin enthaltenen Seiten zu ermöglichen. Ich hab meine 40’000 Seiten bei Google komplett rausgenommen da es weder mit 301 noch mit 404 irgendwie vorwärtsging (bzw. runter). Und jetzt leb ich mal ein halbes Jahr ohne Google Besucher. Aber irgendwie braucht man die auch nicht in einem Weblog.
Die Loesung sollte sowohl unabhaengig vom Browser als auch vom Betriebssystem sein.
Oder surft hier jeder mit M$ und IE ?
Frage an Erika. Welchen Teil ist abhängig vom Browser?
Wenn man http://preview.local.live.com/ ohne Javascript ansurft, kommt auch bei M$ eine Standard IIS 404. 🙂
Der Favorit 4 und der Response Code ist HTTP 404 aber trotzdem verschwinden meine alten Seiten nicht ?? Alles gekenzeichnet mit Zusätzliches Ergebnis in google ??
Hallo Peter.
Die “supplemental results” sind häufig Sorgenkinder – im Bezug auf Aktualität aber auch auf Query- und Raning-Qualität. Einfach gesagt ist es ein langsamerer Indexteil. D.h. Deine Änderungen brauchen mehr Zeit bis sich dort sichtbar werden. Die “supplemental results” sollen zwar besser werden, da ist aber schon lange die Rede davon: http://video.google.com/videoplay?docid=-3494613828170903728