
Ein bisschen verzweifelt werde ich schon, wenn in einer Präsentation das Wort zu häufig vorkommt. “Die Ergebnisse sind nach Relevanz gewichtet”, “…unser Relevanz-Algorithmus stellt sicher…”, oder “…links aussen sehen Sie den Relevanz-Wert”. Eine kurze Übersicht und (hoffentlich) einen Beitrag zur Realität.
Relevant heisst schlussendlich bedeutsam oder wichtig. Aber für wen und im welchen Kontext?
Die Frage nach dem Kontext der Interpretation stellt sich massiv. So erwartet ein Sportfan eine andere Antwort auf die Anfrage “schwarzer Läufer”, als wie eine Person die das Schachspiel lernt oder jemand, der eine Wohnung einrichtet. Oder dieselbe Person zu unterschiedlichen Zeiten. Entschuldigen sie mir das doofe Beispiel, aber der Läufer eignet sich gut, weil er sehr viele unterschiedliche Bedeutungen auf sich vereinigt.
Meist wird Relevanz aber im Zusammenhang mit Suchtechnologie genutzt. Dort gilt es meist einer grosse Menge unstrukturierten Dokumenten zu einer kurzen Anfrage so zu rangieren, dass das wichtigste oben ist. Nach Relevanz für den konkreten User mit einem konkreten Bedürfnis in einem konkreten Kontext. Und all das “konkrete” kennt die Suchmaschine nicht. Deshalb rangiert Google Desktop Search beispielsweise standardmässig nach Datum…
So und nun zur Sachlichkeit mit der folgenden Abbildung (aus dem Buch Informationsbeschaffung im Internet):
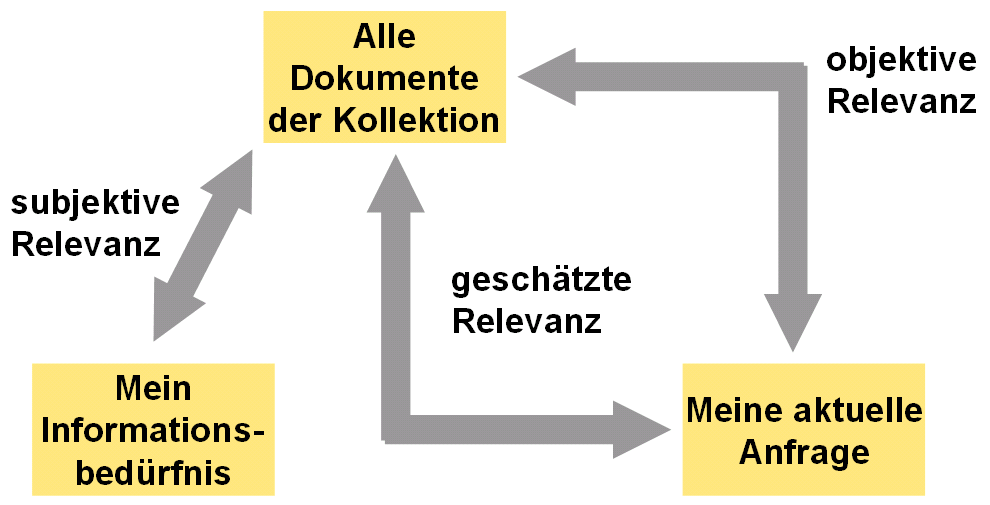
1) Die subjektive Relevanz. Bezüglich meiner Anfrage hier und jetzt an ein Suchsystem habe ich eine klare Erwartung, was relevant ist. So suche ich beispielsweise die Homepage von namics. Ab und zu kann ich diese Erwartung zwar nicht textuell in Form einer Suchmaschinenquery ausdrücken. Bei “namics” ist das wohl einfach.
2) Die geschätzte Relevanz. Das Suchsystem versucht mit Hilfe eines (meist statistischen) Verfahrens zu schätzen, was für mich relevant ist. Dies ist ein bleibt immer eine Schätzung, da das System nicht im mich reinsehen kann. Viele der Suchsystem arbeiten hier sehr simpel. Neuste Ansätze sammeln historische Suchanfragen von mir sowie besuchte Webseiten und versuchen daraus meine Präferenzen zusätzlich in meine Anfrage einzubeziehen. Die Schätzung wird besser, bleibt aber eine Schätzung. So gebe ich (wieder) “namics” in das Suchfeld ein und die Maschine schätzt nun — wegen häufig besuchter Seiten — den namics Weblog als relevanter ein als die Homepage.
3) Die objektive Relevanz ist ein Konstrukt, welches bei der Evaluation von Suchmaschinen benötigt wird. Je nach Ansatz bewertet hier eine Fachjury was relevant sein muss. So könnte sie bei “namics” beschliessen, es sei die Firma in Japan (weil die sicher mehr Umsatz hat 😉
Abschliessend. Eine Rangierung nach Relevanz tönt gut, gehört aber mächtig hinterfragt. Die Rechenregeln mit welchen ein System Relevanz schätzen kann, können beliebig unterschiedlich sein. Oder: Bei News kann eine Datumsrangierung immer besser sein… Keine Wundermedizin aber eine Formel die schätzt…
Wissen Sie: Auf die Relevanz kommt es an!
W
Und was ist Dein Vorschlag zur Erhöhung der subjektiven Relevanz der Suchresultate?
Um bei Deinen Beispiel mit dem Läufer zu bleiben, müsste die Suchmaschine die unterschiedliche Semantik kennen und vor oder zumindest mit den Suchresultaten prominente Links/Filter anbieten für Sportfans, Schachspieler und Wohnungssuchende.
Oder hast Du eine andere Idee?
Hallo David
> Schritt 1:
Den User kennen. Daher speichert Google bspw. alle Suchanfragen (und ordnet diese den angemeldeten Usern zu: https://stuker.com/2005/07/pagerank_und_wi.html). Grundsätzlich wäre auch möglich, dass sie über den Toolbar / Deskbar die Browsebewegungen speichern und Usern zuordnen (tun sie aktuell nicht).
Yahoo macht es mit 360 (http://360.yahoo.com), wo ich selbst den (historischen) Inhalt von Webseiten speichern, meine Bookmarks speichern kann etc. (all dies kann von der Suchmaschine analysiert werden)
Damit kennt die Maschine den User möglicherweise ein bisschen besser, aber nicht den Kontext.
> Schritt 2
Ziel müsste sein den aktuellen Kontext zu kennen und das geht nur mit Fragen stellen. Das Ding läuft unter dem Titel Search-Guide. D.h. gibt der User “schwarzer Läufer” ein, so fragt die Suchmaschine welche Domäne interessiert (Sport, Industrie, Schach, Teppich etc.) Diese Analyse der Frage resp. die Zuordnung des Konzeptes zu Gruppen kann manuell erfolgen, doch gibt es auch statistische Ansätze. Letztere haben bedeutende Schwächen benötigt aber weniger Pflege.
Was auch geht sind Treffergruppen anzeigen (so genannte Strati), womit der User visuell wählen/scannen kann oder sonst eine Art der aktiven Wahl.
> Billige Lösung
Die Ansätze oben sind aufwändig bis unmöglich (d.h. nur bei viel Traffic und guten Quellen möglich etc.) Was ich häufig vorschlage sind deshalb Top-Treffer (im Stil von Google-Werbung) welche redaktionell gepflegt werden und die wahrscheinliche Alternativen die nicht auf der Trefferliste sind, ergänzen
PS. Da werde ich mal einen ganzen Post dazu machen…
Danke für die ausführliche Anwtort – ich bin schon auf den ausführlichen Artikel gespannt…