
Die häufigen Lügen und Fehler bei der Erfolgsmessung von Webanwendungen. Letzter und dritter Teil einer Serie über Web Analytics resp. Online Business Intelligence. In einem ersten Teil erklärte ich bereits einige zentrale Begriffe und im zweiten Teil geeignete Kennzahlen.
Die Erfahrungen zum folgenden Post stammen (leider) aus dem realen Leben. Wer seine Erfolgskennzahlen gut gewählt hat, ist kaum von den “Lügen” betroffen. Also sozusagen ein Post für Leserinnen und Leser, die noch in der Fieberkurven-Welt leben.
Es gäbe zynischere Beispiele, aber hier ein einfacher Case, der ein Teil des Problems zeigt. Annahme: Ich werde gefragt, wie viele Besucher der namics Weblog hat? Die Graphiken unten zeigen die Visits die Woche 5. bis 11. Februar, gemessen mit zwei verschiedenen Tools.
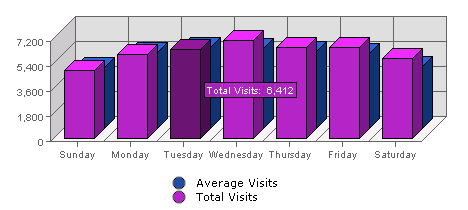
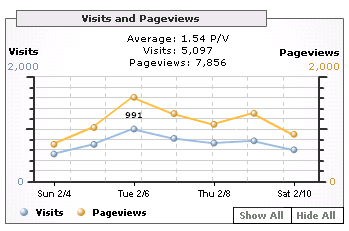
So könnte ich also sagen ich hatte am 6. Feburar 6421 Visits oder ich hatte eben 991 Visits. Welche Zahl würden Sie wählen? Die obere Messung basiert auf der (serverseitigen) Logdatei des Webservers und zählt die Anzahl unterschiedlicher IP-Adressen der Besucher. Eine Adresse ist dann „unterschiedlich“, wenn diese während einem Zeitintervall von 30 Minuten nicht mehr gesehen wurde („Timeout“). Die untere Messung erfolgte clientseitig und misst als einzelnen Besucher jedes, pro Kalendertag neu gesetztes Cookie. Die Messung erfolgt also nur, wenn der Client Cookies annimmt und wenn der Client Java Script ausführt. Dies, da der Tracking-Code mittels Java Script in die Seite integriert ist. Quizzfrage: Wo kommt der Unterschied (mehr als Faktor 6) her? Ein Anhaltspunkt gibt zudem der Tagesverlauf der Visits; Also die folgenden Graphiken.
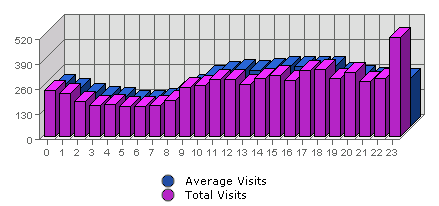
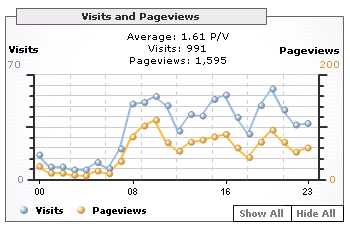
Nehmen sie an, dass die gemessene Website fast ausschliesslich Besucher aus der Schweiz und auch Deutschland hat. Nun, noch andere Ideen zum Unterschied der Zahlen?
Ausgangslage der Serie war ja ein Mensch der sagte mit über 100’000 Hits pro Monat sei ein wichtiger Karpfen im Teich. Der 6. Februar 2007 generierte auf dem namics Weblog übrigens 42,496 Hits auf dem Server. Nun also los zu dem Lügen der Webstatistik (oder weshalb die meisten Site-Betreiber lieber 6412 anstelle 991 Visits melden ;-).
Teil 3: Lügen resp. häufige Fehler bei der Webstatistik
>> Crawler von Suchmaschinen
Suchmaschinen benötigen Inhalte der Websites möglichst vollständig und aktuell. Aus Sicht des Servers verhalten sich die Teil der Suchmaschinen, welche die Inhalte zusammentragen (die Crawler) ziemlich ähnlich wie ein Webbrowser. Allzu häufig werden diese also in Statistiken mitgezählt. Wie erkennen? Die netten Crawler verlangen ab und zu (resp. zu Beginn der Session) nach der Datei /robots.txt und sie haben eigene User Agent Kennungen die ziemlich sprechend sind. Zudem laden diese typischerweise nur die HTML-Grundseite und binäre Seitenelemente wie PDF herunter, aber keine graphischen Seitenelemente (gif/png/jpg) und keine CSS oder Java Script Includes. Ausserdem interpretieren Crawler kaum Java Script und sie nehmen auch kaum Cookies an. Dies erklärt einen grossen Teil des Unterschiedes oben insb. auch die Tatsache, das es bei der „grossen Zahl“ einen Grundlast auch in der Nacht gibt. Das sind in diesem Fall kaum echte Menschen.
>> Verfügbarkeitsmessung des Servers
Es ist üblich, dass die Personen, welche für den Server-Betrieb verantwortlich sind, Verfügbarkeitsmessungen durchführen. So beispielsweise mit einem Tool wie Comparitech oder Nagios oder mit einem Dienst wie Sysformance oder Keynote. Und was machen diese? Sie fordern alle 5 Minuten oder so eine Datei vom Webserver an um zu sehen, ob das Ding tut. Und bei jedem Mal entsteht ein Hit resp. eine Page Views oder gar ein Visit etc. Hier erlebte ich einmal, dass die „Erfolgs-“Statistik von einer Minute auf die andere um mehr als den Faktor 10 einbrach. Als herausgefunden war, dass diese Last immer ab den selben fünf IP-Adressen kam, war rasch klar, dass die Betriebsleute das Monitoring eingestellt hatten. Erkennen lassen sich diese Dienste sonst wie Crawler.
>> Syndikatoren / Feed-Reader
Dieser Aspekt ist vor allem bei Weblogs (resp. allen Diensten die einen Feed z.B. als RSS oder Atom anbieten). Die meisten Feed-Reader besuchen ihre Quellen zyklisch also alle 60 (oder so) Minuten und generieren damit Traffic. Und dies unabhängig davon, ob sich neuer Inhalt auf der Site findet oder nicht. Grundsätzlich machen Syndikatoren wie Planets (z.B. planet.blogug.ch) oder auch Online Feed Reader wie Bloglines oder Google Reader dasselbe. Bei letzteren könnte der Effekt aber auch in die andere Richtung gehen, da der Planet oder der Online Reader einmal bei mir liest und die Information dann mehreren Lesern zur Verfügung stellt. Das Beispiel des Planets bei blogug ist zudem nicht wirklich das Beste, weil sich blogug bei Änderungen aktiv benachrichtigen lässt und somit keine unnötigen Besuche macht. Die Feed-Reader auf den Clients aber schon. Was tun? Vernünftige Kennzahlen oder wie die Crawlern herausfiltern resp. die Anzahl reduzieren. Meistens führen die Reader auch kein Java Script aus.
>> Inhouse Traffic
Und nochmals ein Klassiker. Die Starseite ihrer ganzen Firma ruft die Website auf und so auch die Webentwickler (intern und extern), die Autoren u.s.w. Wollen und sollen sie diese auch zählen? Ja nachdem filtern sie lieber die entsprechenden IP-Adressen.
>> HTML Frameset
Das Ding ist zwar alt (und sollte nach meiner Meinung nicht mehr benützt werden). Technisch gesehen generiert ein Frameset beispielsweise mit 3 Frames (Top, Naiv, Content) aber pro Ansicht im Browser drei Seitenaufrufe (einen pro Frame). Ohne Gegensteuer verdreifacht sich also die Anzahl der Seitenansichten zu Unrecht. Filtern kann schwierig sein, da kaum alle Seiten gleich viele Frames haben…
>> Reloads
Früher was das mal ein Tick. Mittels des Tags „Meta Refresh“ wurden v.a. Portalseiten alle x Minute clientseitig neu geladen. Das Argument war möglicherweise, dass die Aktualitäten gezeigt werden sollen. Häufig diente es aber auch dazu, den „Traffic“ unsinnigerweise zu vervielfachen.
>> Caching
Je nach Infrastruktur werden gewisse Seiten oder Seitenelemente aus Effizienzgründen in vorgelagerten Proxies zwischengespeichert und lokal ausgeliefert. Das ist auch gut so und wenn kein echter Bedarf besteht, sollten diese Mechanismen auch nicht umgangen werden (z.B: mit Zufallszahl in der URL, mit meta no-cache, mit Manipulation von ETag etc.). Der Webserver (und damit seine Logdatei) sieht die Requests nicht mehr. Ein clientseitiges Tracking aber schon.
>> Echter Beschiss
Und natürlich kann die Statistik absichtlich verändert werden. Es ist technisch sehr einfach möglich auf einem System Last resp. Klicks zu generieren. Aber das wäre wohl ein eigener Post und da haben schon ein paar dazu gesprochen z.B. Bruce Schneier zu Google Click Fraud.
Von Hundertsten ins Tausendste… Aus irgend einem Grund könnte ich zum Thema Lügen noch lange weiter schreiben. Aber belassen wir es mal dabei.
Web Statistik: Begriffe, Kennzahlen und Lügen (aka Web Analytics oder Online Business Intelligence) – Teil 3 von 3
W
Ein beliebter Traffic-Lieferant ist auch Google-Adsense. Das schaut regelmässig vorbei um die Werbung wieder zu aktualisieren. Ein schöner Effekt bei Blogs, die ja meistens Adsense als (Nicht-)Einnahmequelle vorsehen.
Endlich mal eine (ziemlich) umfassende Darstellung der Web-Statistiken, welche auch einem Halb-Laien in den Kopf geht. Vielleicht kommt irgendwann noch ein vierter Teil mit einem Vergleich der verschiedenen Tools? Was ist der Unterschied zwischen w3counter.com, blogcounter.de und anderen Tools?
Jürg
Sehr gut, die Serie sollte von jedem Blogger mit Business-Ambitionen gelesen werden, denn allzuhäufig noch basieren die Online-Schwanzlängenvergleiche noch auf völlig untauglichen Kennzahlen wie den Hits.
Für die Fortgeschrittenen wäre dann interessant zu hören, weshalb unterschiedliche Anbieter wie Hitwise, Comscore, Alexa oder Google Analytics immer noch unterschiedliche Zahlen liefern…
Danke für die netten Kommentare.
Die unterschiedlichen Ergebnisse der Tools lassen sich mit den drei Post meist beantworten. Punkt 1 ist der Prinzipunterschied Tracking-GIF versus HTTP-Log (was es sonst noch gibt ist im Proxy [trasnparent oder mit rewriting] und in der Anwendung selbst). Punkt 2 sind dann Detailunterschiede insb. der Umgang mit Cookies und Java Script sowie das Timeout-Intervall bgzl. Sessions/Visits vs (unique) Visitors. Und sonst noch ein paar Details wie Realods, Caching u.s.w.
Ich habe bin jetzt bewusst die Tools weggelassen. Grund ist, dass ich mit einem guten Gewissen nicht einfach Tools vergleichen kann, dies aber nur anhand einzelner Kriterien machen könnte. Wer will was? Aber ganz ehrlich: Wenn die Kennzahlen gut sind (z.B. Anzahl Bestellungen) dann ist das Tool zweitrangig.
Müssten die “Visits” des / der RSS-Feeds bei solchen Statistiken nicht generell mit ausgewiesen werden?
Zwar lesen diese Leser den Inhalt nicht im Browser, aber sie lesen und besuchen die Website indirekt. M.E. sollten diese Visits bei solchen Statistiken zur Vollständigkeit zusätzlich ausgewiesen werden.
Dabei ergibt sich die Schwierigkeit der Messung, wobei teilweise durch Dienste wie MyYahoo, Google Feedfetcher zumindest die Anzahl der Subscriber rückgemeldet werden… Andererseits scanne ich beispielsweise oft Artikel im Feed-Reader, lese sie dann jedoch im Browser (Doppelzählung?). Außerdem teste ich gerade einen weiteren Feed-Reader Eldono (ebenfalls Doppelzählung). Weiterhin kann ein Volltext-Feed u.U. auch auf anderen Websites syndiziert sein.
Über Feedburner ergeben sich für mein Blog angeblich ca. 30 bis 40 Prozent weitere Leser, aber aufgrund der angerissenen Zählproblematik können das de facto auch nur 5 bis 10 Prozent sein.
Bringt das Lesen bzw. die Syndizierung per RSS durch die zunehmende Verbreitung nicht die ganze Thematik Statistiken / Web Analytics / Reichweitenmessung durcheinander?
Feeds (inkl. RSS) bringt die Reichweitenmessung klar durcheinander… Diese “Messungen” waren meist aber sowieso alles andere als zuverlässig (so von wegen Werbedruck uns so ;-).
Am einfachsten wäre es, die Feeds (meist ja eine kleine Anzahl URIs) separat auszuweisen. Dann kann sich jeder seine Geschichte bezüglich Doppel- oder eben Bruchteilzählungen (was ist das Wort bei n
Mein Provider hatte ein paar Tage lang technische Schwierigkeiten mit dem Webstat AWStats. Dann schlug er mir vor, doch auf Smarterstats zu wechseln, das habe auch noch viel mehr Möglichkeiten. Und siehe da auf einen Schlag hatte ich fünfmal mehr Website-BEsucherInnen!!!!
Dank der super-Erklärung weiss ich nun auch, wieso. JEtzt würde mich nur noch interessieren, wie ich meine eigenen Zugriffe und die der Webrobots von Google und Co rausfiltern kann, damit ich letztlich auf die wahren, die “echten” Besucher komme…
liebgrüsslis
Eveline
Gern geschehen und bei Fragen bin ich jederzeit hier.
Danke für die verständlichen Begriffserklärungen, die haben mir als Allerleiblogger am meisten genutzt. Auch bei den Ausführungen über die Lügen gab es noch einige Aspekte, die ich mir merken werde.
Und ja, lieber spät als nie kommentieren… 😉